Advances in general-purpose machine learning have largely been spearheaded by models based on the transformer architecture. These models have proven extremely impressive in their capabilities; however, they have a fundamental limitation. A transformer does not maintain state between requests, meaning that beyond its initial training and context window, it has no memory. In addition, it completely lacks temporal continuity between interactions.
In this work, I explore the Continuous Neural Graph (CNG), a stateful spiking neuron graph that relies on Hebbian Learning and Lamarckian Evolution to learn how to compute a function.
To evaluate this approach, I built and trained a small twenty-neuron graph on Boolean operations, including the non-linear XOR and NAND, to assess its ability to learn basic functions. The system demonstrated the ability to learn each of these functions at perfect accuracy while maintaining continuous state. However, the graphs even without sequential
While limited in scope, these results suggest that this architecture can approximate both linear and non-linear functions while maintaining continuous internal processing and state.
Related Works
The dominant paradigm in modern machine learning is the transformer architecture, introduced by Vaswani et al. [1] in Attention Is All You Need. Transformers process input sequences via self-attention mechanisms and have achieved remarkable results across language, vision, and reasoning tasks. However, as described below, they are stateless between calls and require the full context to be re-fed on every interaction.
Recurrent architectures such as Elman networks and Long Short-Term Memory [2] were designed precisely to address the statelessness of feed-forward networks. LSTMs maintain a cell state across timesteps and were the dominant sequence modeling approach before transformers. However, they are still trained via backpropagation through time, which requires unrolling the network and performing a global gradient update — incompatible with continuous, uninterrupted operation. In practice they are applied in fixed-length episode windows rather than as truly perpetual processes.
Spiking Neural Networks (SNNs) represent a closer biological analogue to the CNG. First formalized as a computational model by Maass [3], SNNs use discrete spike events rather than continuous activations, operate asynchronously, and can in principle run continuously. Much of the literature on SNNs focuses on neuromorphic hardware implementations such as Intel's Loihi and IBM's TrueNorth, which exploit the energy efficiency of spike-based computation. The CNG draws on the spiking neuron model but differs in its emphasis on in-life learning and evolutionary topology search rather than hardware efficiency.
Hebbian Learning, introduced by Donald Hebb [4], provides the in-life learning mechanism for the CNG. The principle — that synaptic strength increases when pre- and post-synaptic neurons fire together — has been extensively studied in computational neuroscience and forms the basis of several unsupervised learning rules. The CNG extends this with a global reward/punishment signal to provide task-directed credit assignment without backpropagation.
The NeuroEvolution of Augmenting Topologies (NEAT) algorithm [5] is the closest precursor to the evolutionary component of the CNG. NEAT evolves both the weights and topology of a neural network through genetic crossover, mutation, and speciation via historical gene markers. The CNG's Lamarckian Evolution is directly inspired by NEAT but departs from it by preserving in-life learned weights across generations and forgoing neuron-count complexification in order to maintain continuous graph operation.
Continual learning — the ability of a system to learn new tasks sequentially without forgetting prior ones — is an active area of research. A central challenge is catastrophic forgetting [6], in which training on a new task overwrites weights relevant to previous tasks. Approaches such as Elastic Weight Consolidation [7] address this by penalizing changes to weights deemed important for prior tasks. The CNG approaches this differently: because learning occurs continuously via local Hebbian rules rather than global gradient updates, the graph is not subject to the same discrete task boundary problem, though sequential multitask learning remains undemonstrated.
The Problem
Your favorite LLM is murdered and resurrected with every single message. This is not a flaw within the system; rather, it is inherent to the transformer architecture. Whenever you send a message, tokens are fed into the transformer via the context window. After processing, the model spits out another stream of tokens until it reaches the stop token, then ceases computation entirely. Whether the computer is on or off makes zero difference. Indeed, if one were willing to take the time, the model could be freshly loaded from cold storage with every prompt.
This means that outside of the context window a model cannot maintain persistent internal state. A single model can be used by any number of people simultaneously with no awareness of this, as the entire interaction is fed in as if it were reading the transcript of someone else's conversation. Even a simple game such as Memory can only be played in a contrived manner because the model has no task-dependent memory — only context and baked-in weights.
When a human plays the game Memory, each button is lit up in sequence so that the player never sees the entire sequence at once. For a transformer, however, every element of the sequence must be present in its context at the same time. Thus, it is not really remembering; it is merely repeating back the list it was given.
As such the primary solution is to use a bolt on strategy where external methods are used to inject context within the model. This usually takes the form of using rag to search a knowledge base for relevant documents to the question asked. In addition, MCP is another way giving the model knowledge of tools in which it can either interact with its environment or poll for additional information. However, both of these and other methods of context injections have the issue in that they are not built within the architecture, rather, bolt on methods used to patch this fault within the architecture. In addition, due to the attention parameter, injecting a large amount of context, as is necessary for many applications, will lead to a loss of efficiency with the middle of the prompt often being overwhelmed by the first and last portions of the context window.
Many of the architectures share this bolt on limitation such as Neural Turing Machines. They utilize attention over an external memory matrix to read and write information as state. While there has been improvements made, they share the same limitations as context injecting in addition to being more volatile.
// I guess talk about Mamba. Mamba has been an attempt to introduce within the
As mentioned above, the current Machine Learning paradigm is based upon a query response model. (idk add a description of limitations ig?)
An Additional Approach?
With the current machine learning paradigm being based upon the query response model, there has been little to no investigation into the approach of using a continuously operating system. As in, the system not only is holding state from the last query, but is actively processing the information while awaiting the next query. This means not only does a continuously operating approach hold state from the last query to be used during the present, but also continues to operate upon it. As such it has the prerequisites to have genuine short term memory without resorting to context engineering work arounds.
As an additional advantage over even Mamba, the previous queries are being processed in the interim. This means that the internal state, beyond being persistent, is changed based upon previous queries and the model. Theoretically, this could lead to advantages in long tasks as the model maintains a continuous chain of thought. Crucially, there is not the cognitive tax of transfering the way the model thinks, in pure math, back into the semantic tokens and human language. The rich and many dimensional way of simulating reasoning is compressed into a stream of tokens. Continual processing however means that the previous responses remain in some way inside of the model in a more full form. This means that transformers even if they could develop complex mathematical representations of concepts, they are flattened with every query. On the other hand, architecturally, continuous operation permits the retention of the full representation of the model's method of reasoning.
Given the constraint discussed above, any continuously operating machine learning system cannot utilize the current methods of machine learning. Right now, these methods in order to cycle information must place the information back into the front in the form of a new query as the information is fed in one way. To have continuous operation without the addition of new information, the architecture must therefore loop such that information is passed between layers. This means that the model has possibly never shut down. It does however have two complications.
The first is that this becomes proportionally computationally expensive. While as mentioned above, a modern machine learning system between queries could theoretically be living in cold storage, meanwhile an internally looping system would have to always be computing. As such the expense of running the system is not relative to it being used. This favors approaches that are computationally cheap.
The second is that the model must have internal loops. This supports a graph style network instead of a more linear, layer based passforward approach. Instead, the inputs will feed in a loop throughout the model. However, this has the issue in that the information could find itself into a feedback loop resulting in an explosive rise of activity and thus erasing all useful information. Alternatively, the activity could gradually drop off until the model has 'died'. In essence, the system must walk the knife's edge between epilepsy and death.
However, there is a final constraint imposed by the nature of a continuously operating system. The current default learning(?) methods all presume that the system stops for the back propagation. This introduces both discrete update phases and global coordination — a direct contradiction to the principle of continuous operation. Such a machine would have to either sacrifice all plasticity or sacrifice continuous existence. Naturally, as the system is both processing and learning this further increases the computational requirements.
As such, whatever form a continuously operating machine learning would take, it is necessary to find solutions to the above obstacles.
Continuous Neural Graphs
To this end, I have developed the Continuous Neural Graph. It is a neural network architecture in which each node's connections are unconstrained by layers, meaning they are free to loop and connect as they desire. Each neuron is a spiking neuron that activates when the weighted sum of its incoming connections exceeds its firing threshold:
// We need formulas
where wᵢ is the weight of each incoming connection, xᵢ is 1 if the connected neuron fired on the previous tick and 0 otherwise, and θ is the neuron's firing threshold. This activation propagates through downstream connections, each carrying its own weight. Neurons can be either excitatory or inhibitory: excitatory nodes add to the weighted sum of their downstream neurons, while inhibitory nodes subtract.
Each graph has dedicated input and output neurons. Input neurons are fully controlled by the environment and do not accept incoming connections, while output neurons are read to determine the result of an operation.
The graph operates on discrete ticks. On each tick, every neuron is simultaneously evaluated using double-buffering so that each activation is computationally an independent event.
Learning Mechanism
A graph's behavior is primarily determined by three parameters. First is topology: while the number of neurons is currently fixed, the connections between them must be shaped to suit the task. Related to this is the classification of each neuron as excitatory or inhibitory. Second is connection strength — the weights on each edge. Third is each neuron's firing threshold.
Hebbian Learning
The above method is grounded in the principle of neurons that fire together, wire together [4]. The CNG uses a derivation of this approach in which each neuron tracks when it last fired. Upon receiving a correct or incorrect output signal, a global reward (dopamine) or punishment (pain) signal is broadcasted to the entire graph. Because each neuron tracks its last firing time, the graph can cheaply assign credit to the neurons that contributed to the outcome and adjust their connection weights according to the following formula.
// Insert the formula
Without backpropagation, the graph is still able to assign credit for correct and incorrect outputs and modify itself in response. The introduction of an answer key provides the feedback needed to generate reward or punishment signals, upon which the graph self-modifies.
This learning method is well-suited to the CNG because it allows the graph to continue learning while running continuously. To enable at least some modification of the topology during life, when the weight of a connection falls to zero, the connection is pruned. Constructive topology modification via Hebbian principles could theoretically be added however, I chose not to implement it for this experiment due to complications of which neurons should choose to wire together.
Lamarckian Evolution
For determining topology, the current standard is the NEAT algorithm [5], which uses Darwinian evolution to evolve both topology and weights based on a reward function, guided by the principle of complexification in which neuron count grows continuously.
However, since the number of neurons in a CNG is fixed at creation, the complexification component of NEAT must be set aside. Rather, topology is modified purely through connections. Using pure genetic crossover would cause Hebbian-pruned connections to be re-introduced, undermining the pruning mechanism. Eliminating Hebbian Learning in favor of pure NEAT would, in turn, require halting the graph entirely for each evolutionary update — contradicting the requirement for continuous operation.
Instead, the CNG uses a modified evolutionary scheme. At defined intervals, lower-performing graphs are eliminated and the top performers are bred using Jaccard similarity to approximate NEAT's speciation mechanism. Mutations are then applied to pull graphs away from local optima and to introduce new connections into the topology. Crucially, connections are not pruned during breeding.
// Formulas
This is Lamarckian in that weights and connections learned through Hebbian Learning are preserved across breeding and mutation. This allows both continual in-life learning and evolutionary pressure on topology. If a graph happens upon an ideal topology, its learned experiences propagate to its descendants. While this does not guarantee strict continuous learning, it preserves learned state across generations while allowing survival of the fittest to govern topology.
Homeostatic Plasticity
In early iterations, graphs would either fall completely silent or enter a runaway firing state resembling an epileptic seizure. In both cases the graph had failed to hover at the knife's edge between death and epilepsy. To correct this, the following formula was used to modify the neuron's spiking threshold:
// Formulas
To prevent runaway feedback between connection strength and threshold adjustment, thresholds above a certain level increase logarithmically, providing a soft cap using the following formula.
// Formulas
Viability Checks
A recurring problem during testing was the emergence of oscillators—graphs who regardless of input would cycle one of the outputs on or off. This was largely due to two factors. First, the training data was truly random, meaning that with a large enough sample a pure random-firing graph could achieve up to 80% accuracy. I inadvertently fell into this local optimum, tweaking parameters to push this number higher without realizing the root problem until I serialized and visualized the graphs.
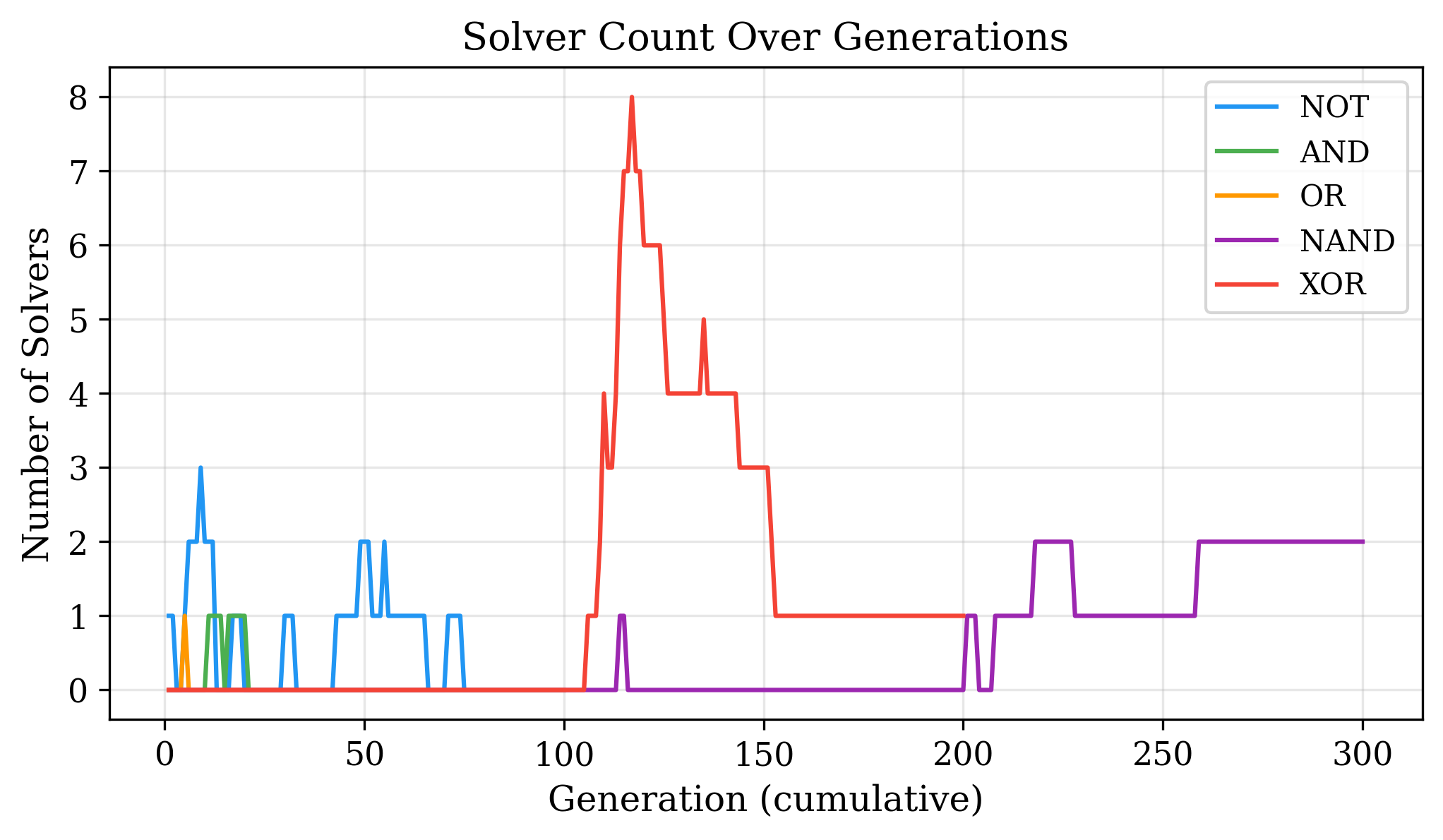
In the current CNG, any graph deemed non-viable — meaning it is disconnected from at least one input or output — is immediately terminated. This was combined with a randomized queue (Maybe do a formula here? idk) that cycles through all training examples once before repeating, in a random order. Thus the local optimum cannot be higher than the percentage of time flashing one output would score. As such any graph that genuinely surpasses the local optimum will theoretically rapidly outcompete oscillators. Knowing the local optimum fitness also provides a clear signal when a run is stuck.
Catastrophic Extinction
Despite the theoretical, often a graph would break through the local optimum only to be driven back down by random chance, leaving a fitness peak in the middle of the training curve. To address this, the best-performing graph ever recorded was preserved and used to seed a subsequent run, initializing that run with the offspring of the champion alongside the champion itself. This is a form of Checkpoint Evolutionary Recovery though Catastrophic Extinction is the more dramatic name. While this occasionally needed to be repeated, it proved effective at solving the more difficult functions, as shown in the results below. This however speaks to an inherent limitation of the graph in is inclined to fall into the local optimum. As discussed later below, an adjustment to the reward function helped but did not eliminate optimizing for the local optimum. Such an issue will have to be addressed.
Summary
Given the strict requirements outlined above, the current version of the Continuous Learning graph requires two in-life learning systems running simultaneously — Hebbian Learning to adjust weights and prune connections, and Homeostatic Plasticity to keep firing rates stable — along with an evolutionary system to shape topology across generations. Viability Checks and Catastrophic Extinction serve as essential safeguards against the proliferation of degenerate or locally-optimal graphs. Indeed, I added the last two along with Homeostatic Plasticity during prototyping to fix errors that manifested themself.
The Experiment
As the architecture of the CNG is entirely novel, the first barrier is the ability to demonstrate function approximation at any scale. The simplest primitive functions — which when combined can produce any computable operation — are the Boolean operations. As such, the experiment attempts to train five separate graphs of twenty neurons each on the five primary Boolean operations:
- AND
- OR
- NOT
- NAND
- XOR
The last two represent the most significant functions for the CNG to approximate. NAND is functionally complete: any Boolean function can be constructed from it alone. Furthermore, in a recurrent structure, a NAND gate can be used to build a latch, granting the graph one bit of persistent memory. XOR is significant because it was the non-linear function that exposed the fatal weakness of the original Perceptron and remains a benchmark for the ability to learn non-linearly separable functions.
AND and OR also present a meaningful test: a graph that always outputs a constant value can achieve a local optimum of 75% accuracy. By learning these operations correctly, the CNG thus demonstrates that it can break through these false ceilings.
Together, these functions test whether the CNG can learn both linear and non-linear functions while avoiding local optima.
Experimental Setup
Each function is evaluated by training a separate graph of twenty neurons. Each graph is either initialized randomly or seeded from a previous run's best performer. Each graph has three inputs — or two in the case of NOT — and two outputs. The extra input and output were introduced because the graph runs continuously and has no architectural way to distinguish between null input and silence. A third input therefore serves as a clock signal, firing whenever the model is being queried. Likewise, to prevent silence from being inadvertently rewarded, outputs are one-hot encoded as True and False.
This gives the following inputs:
- Clock
- Input A
- Input B
And the following outputs:
- True
- False
Each input is held active for twenty ticks, followed by eighty ticks of silence during which the graph is expected to produce its answer. It is then evaluated and scored using the following formula.
// Formulas
A concern was that a graph might learn to deliberately give a wrong answer before self-correcting to earn a higher cumulative reward, but this behavior never emerged during the experiment.
// TODO: Insert final hyperparameter table.
Results
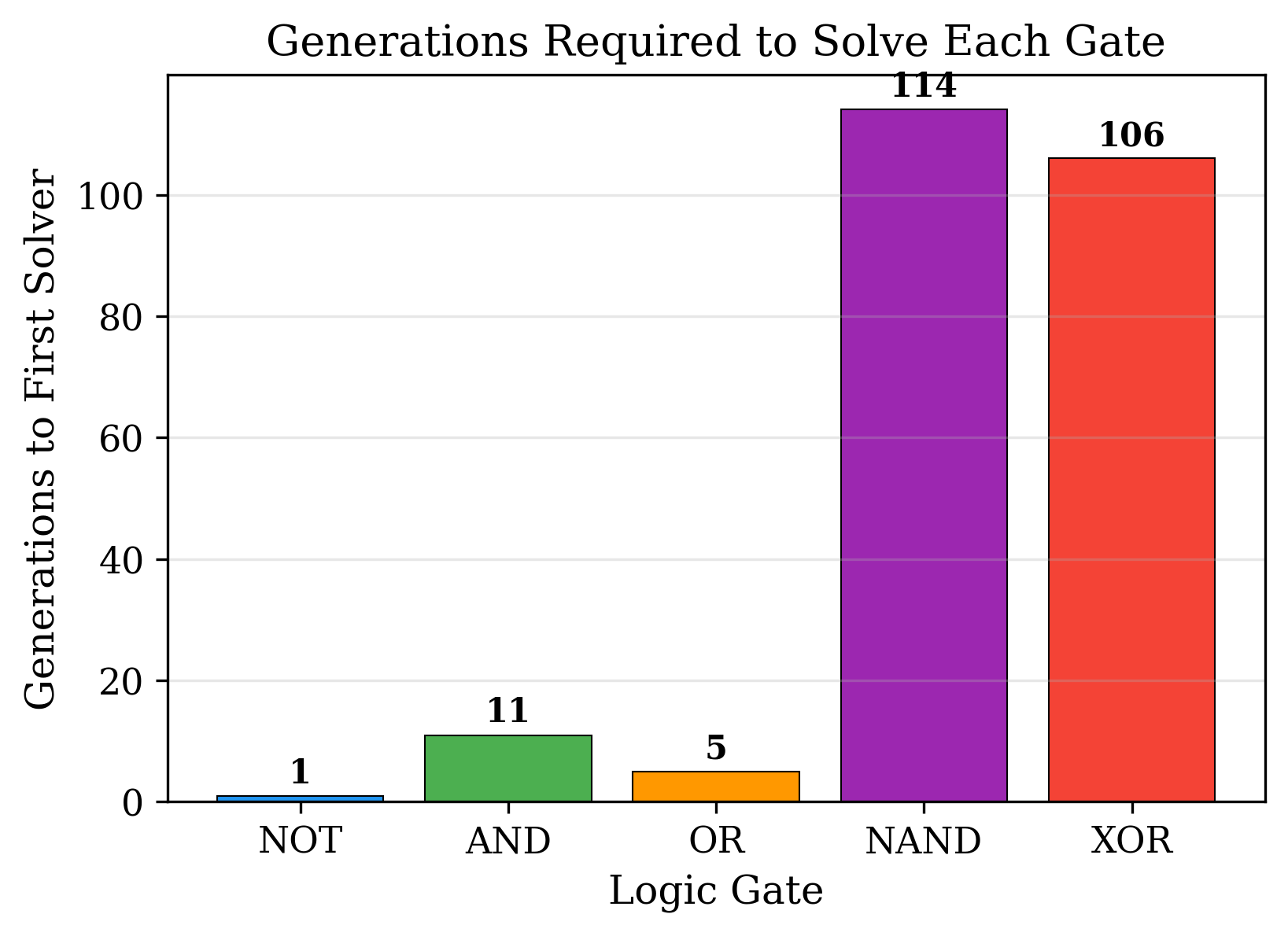
Initially, the AND gate resisted approximation. Even with repeated Catastrophic Extinction events to reseed the population, graphs consistently fell into the 75% local optimum and could not escape.
To address this, the reward function was tuned in two ways. First, drawing on Kahneman and Tversky's finding that losses feel psychologically approximately twice as powerful as equivalent gains [8], the reward signal was set to double the punishment signal. This makes experimentation less costly, encouraging graphs to try riskier topologies rather than settling into a safe local optimum. Second, the reward for a correct output was made inversely proportional to that output's frequency in the training data. For example, since the False output is three times more common than True in AND training data, a correct True output yields three times the reward of a correct False output. This prevents the graph from gaming its score by defaulting to the majority class. The scoring formulas above reflect these changes rather than the initial reward function.
The combination of these two modifications, together with Catastrophic Extinction checkpointing, enabled the model to solve all five gates — including the non-linear XOR and the functionally complete NAND — each achieving 100% accuracy on the full truth table.
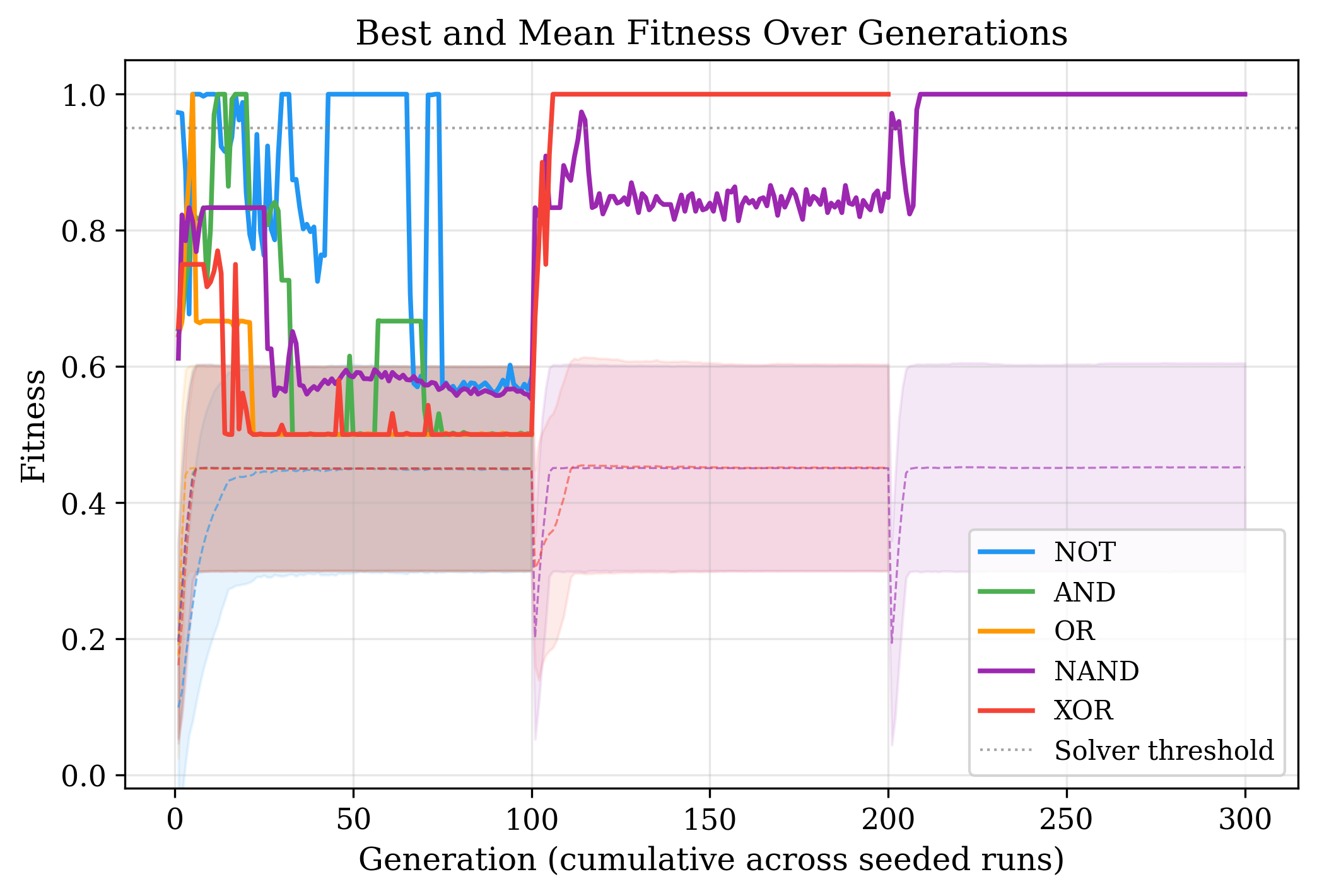
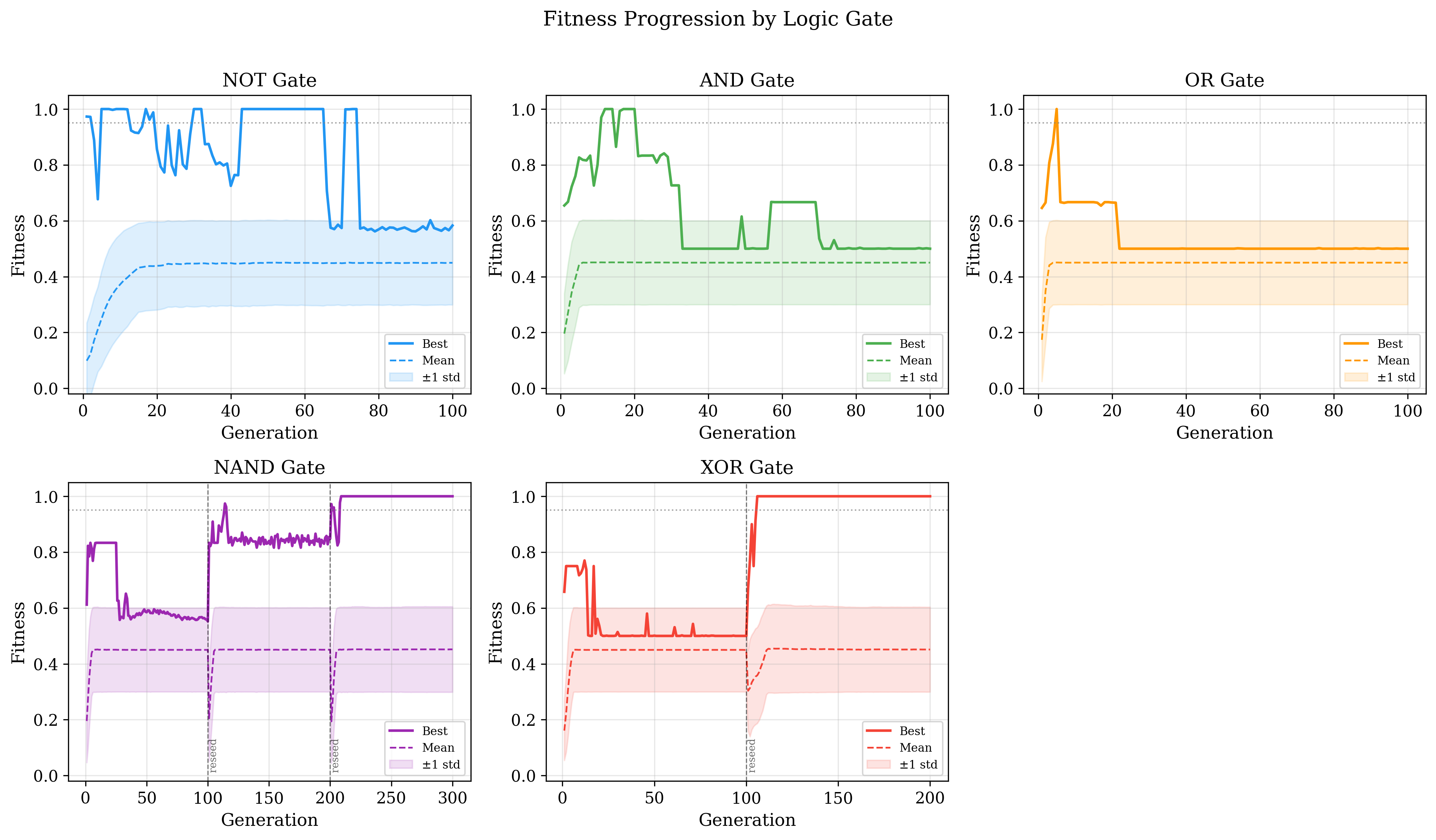
//TODO: Edit the caption to reflect the graph
Analysis
The successful training of all five Boolean gates — including the non-linear XOR and functionally complete NAND — demonstrates that the CNG can learn both linearly and non-linearly separable functions. Because any Boolean function can be expressed as a combination of these operations, this result implies, at least in principle, that the CNG can learn any such function. However, this presumes that the model will scale with the difficulty of the task.
The structural evolution of the graphs over training reveals patterns consistent with their task demands.
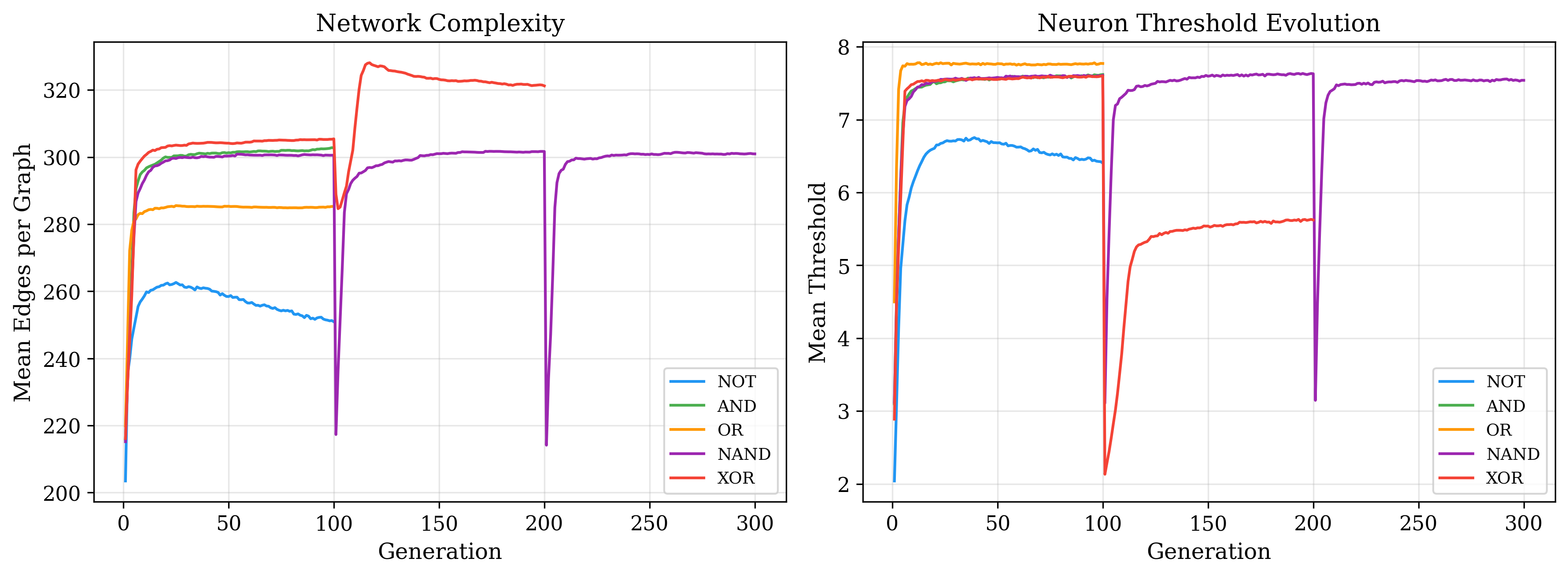
The evolved network topologies below show the active connection paths in the best solver for each gate. Simpler gates developed sparse, direct routing from inputs to outputs. The more complex gates evolved denser inhibitory structures, consistent with their need to compute non-linear decision boundaries.
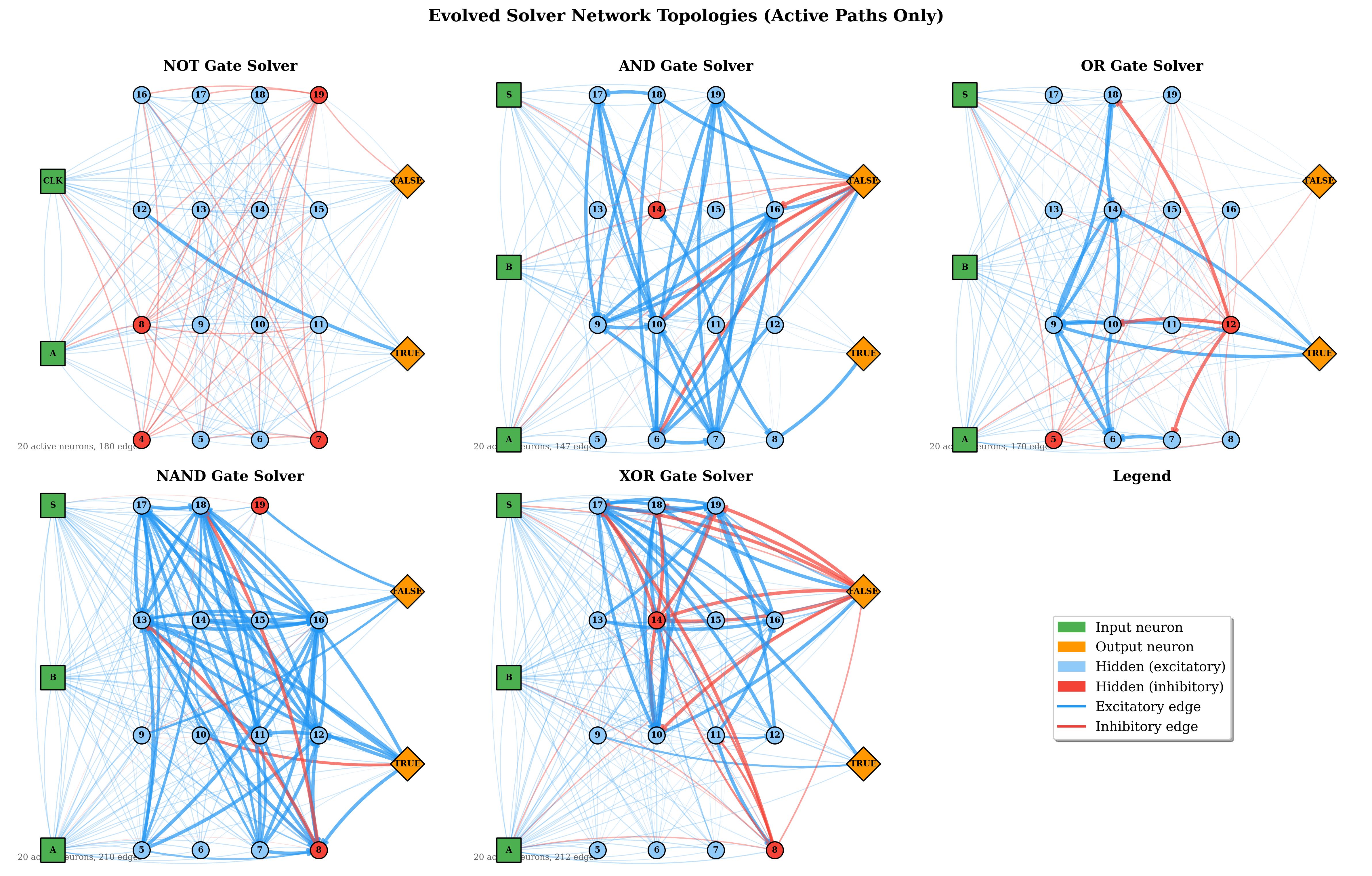
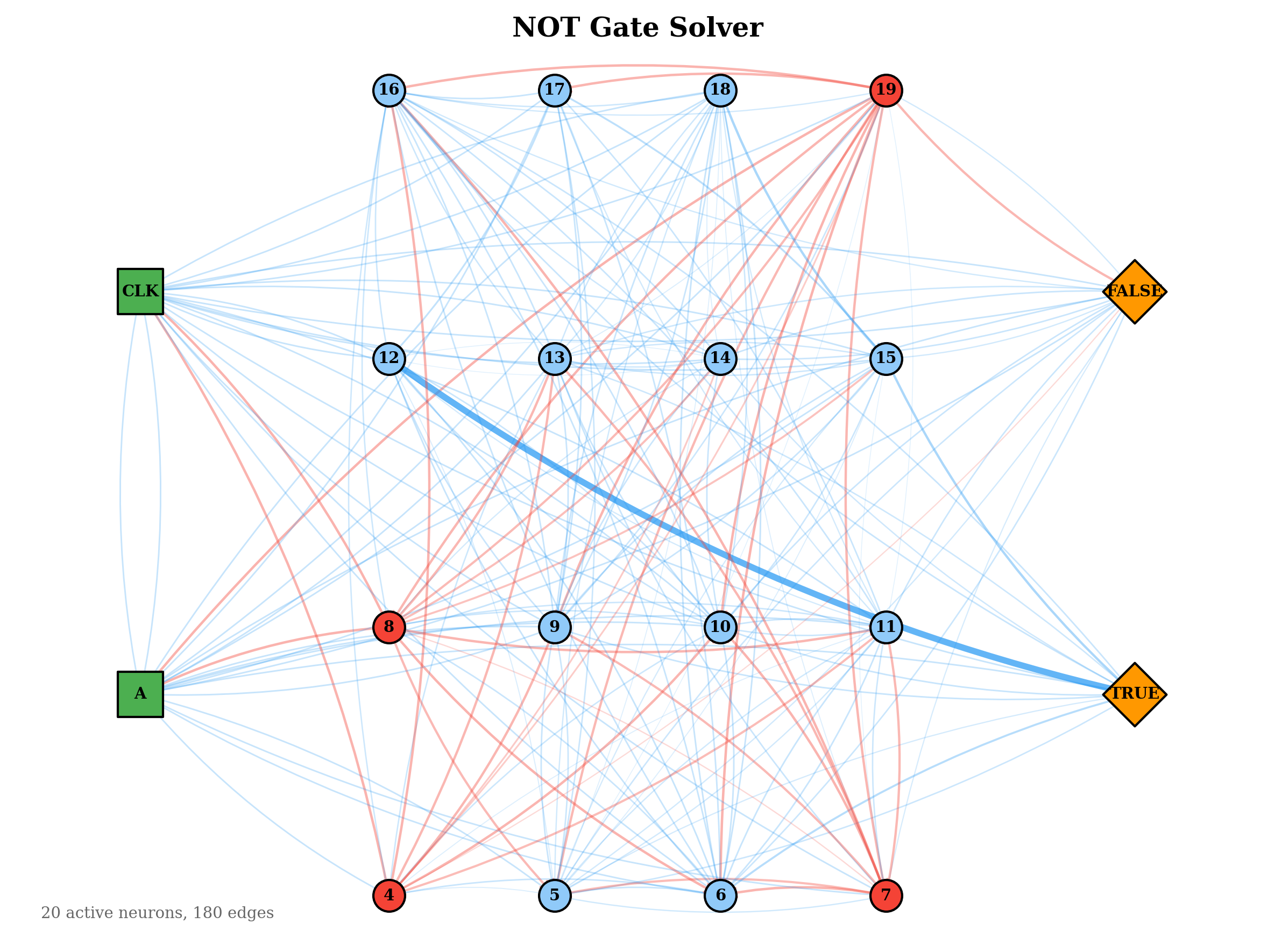
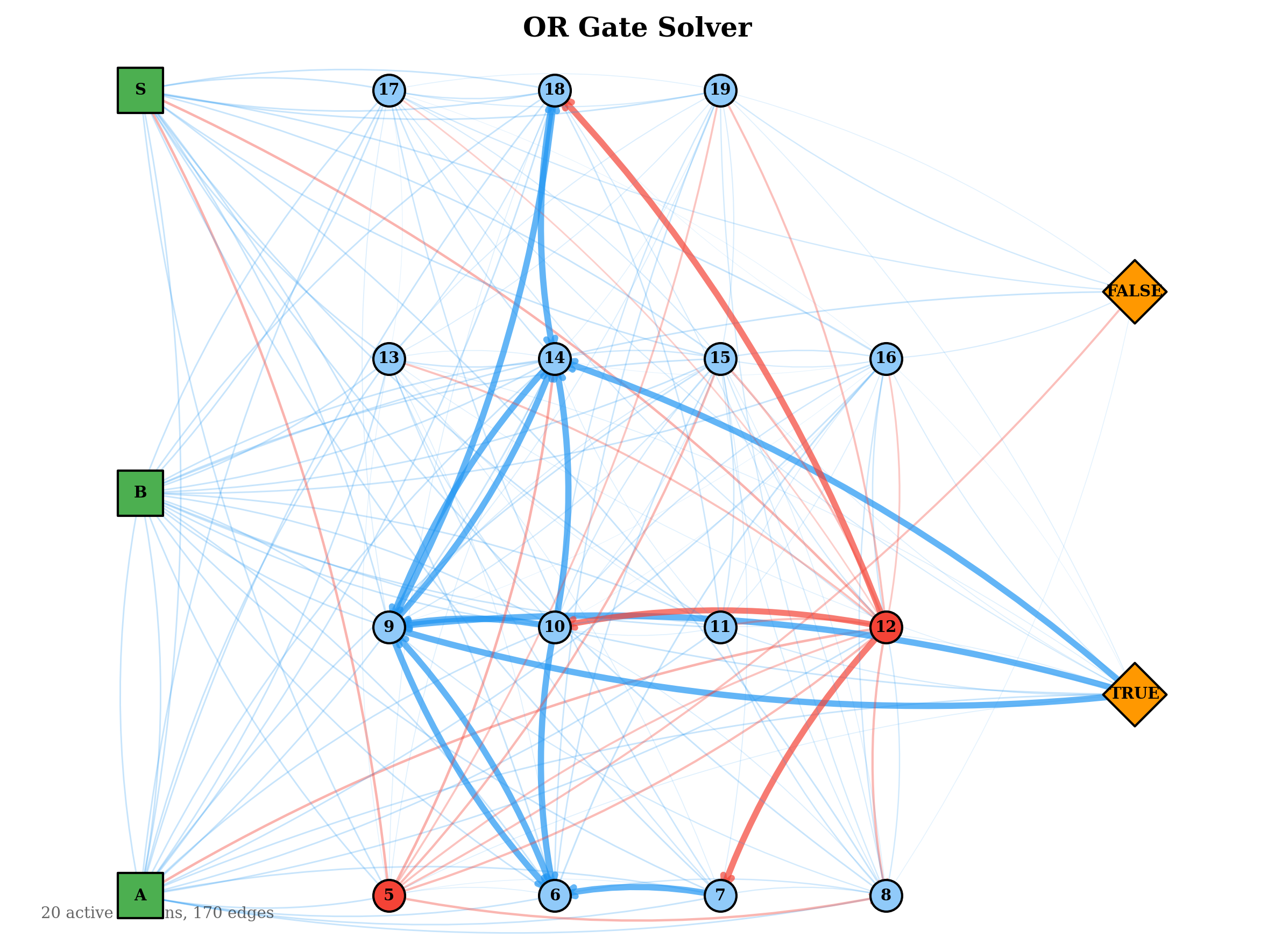
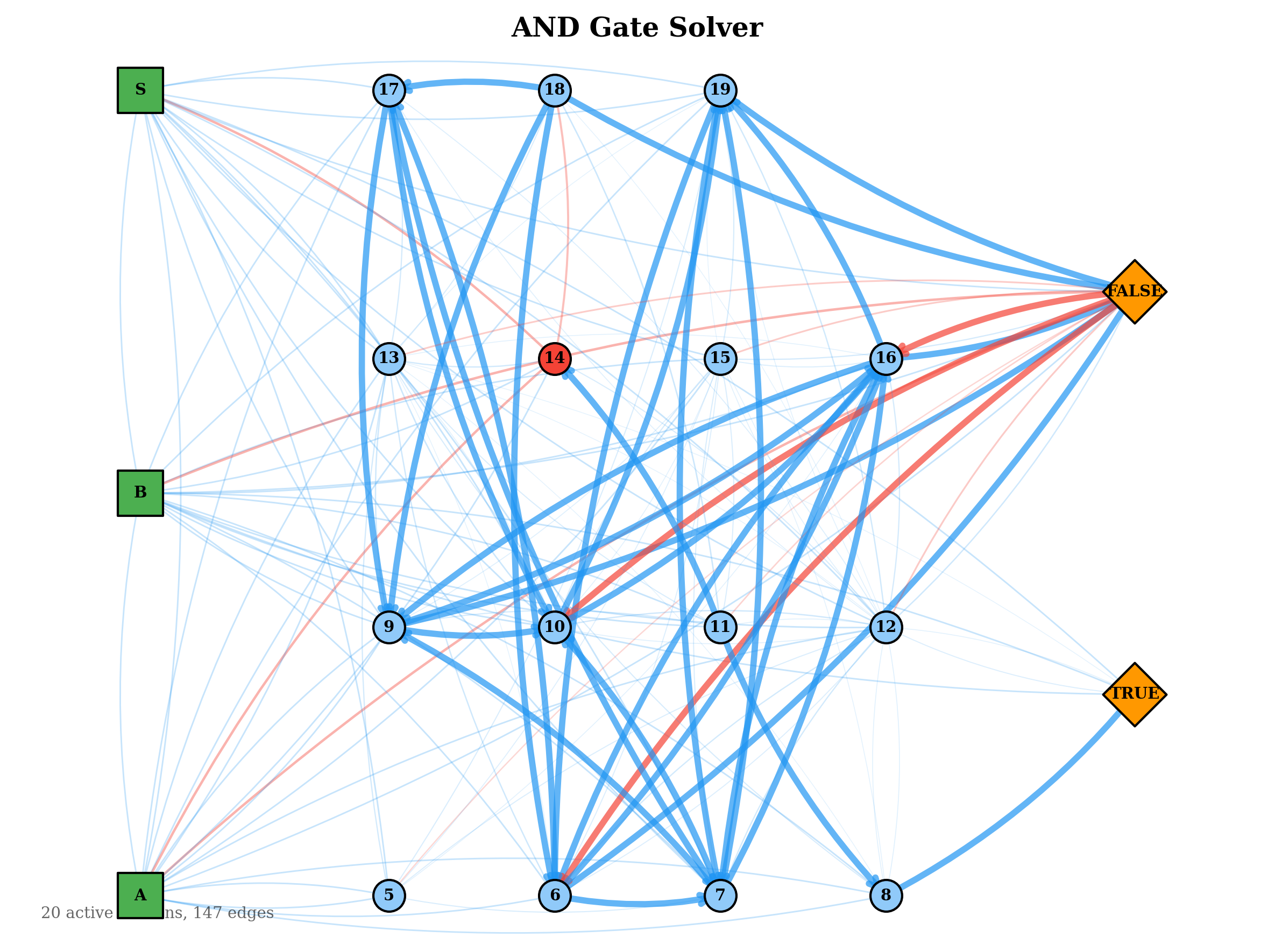
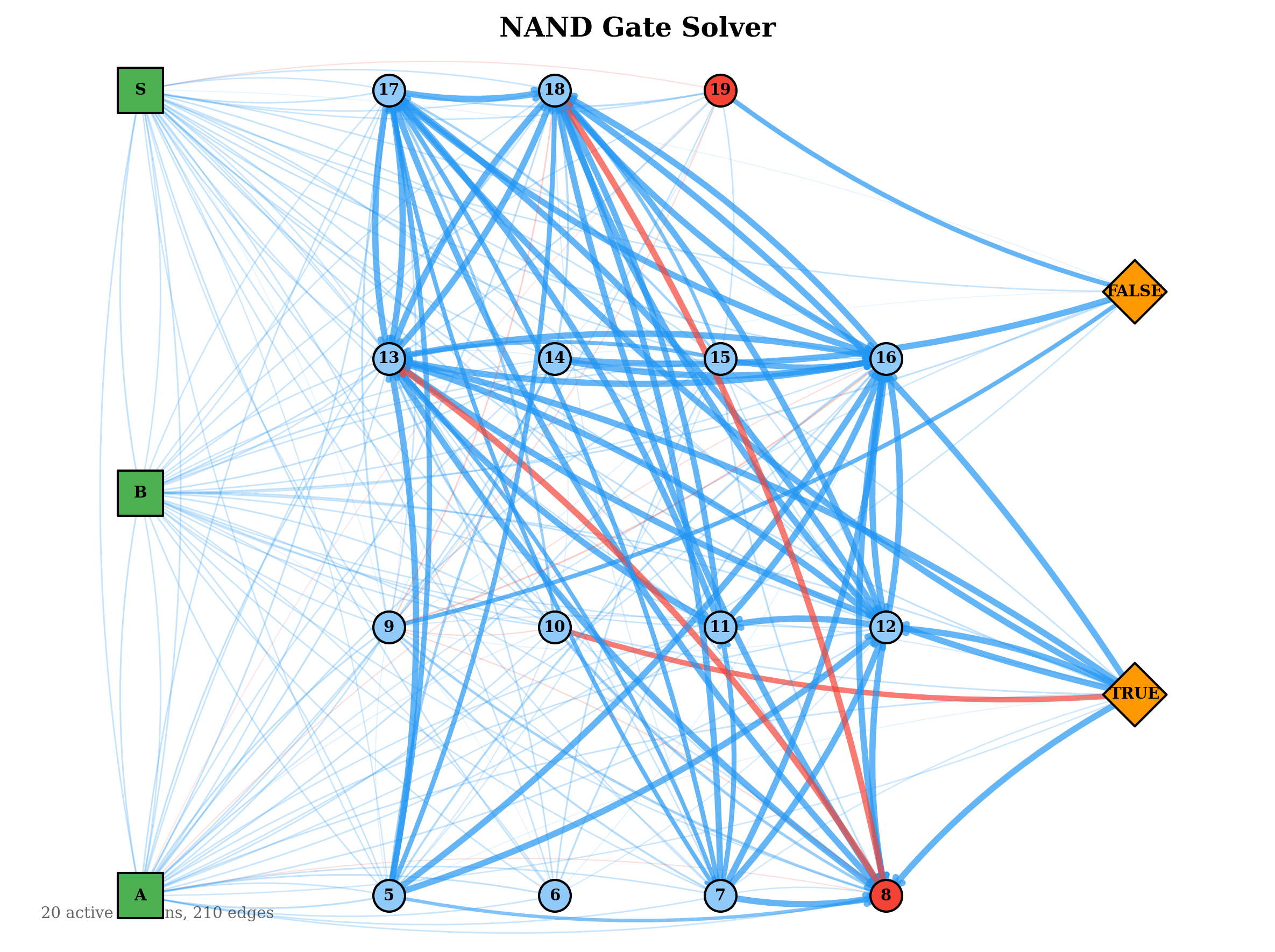
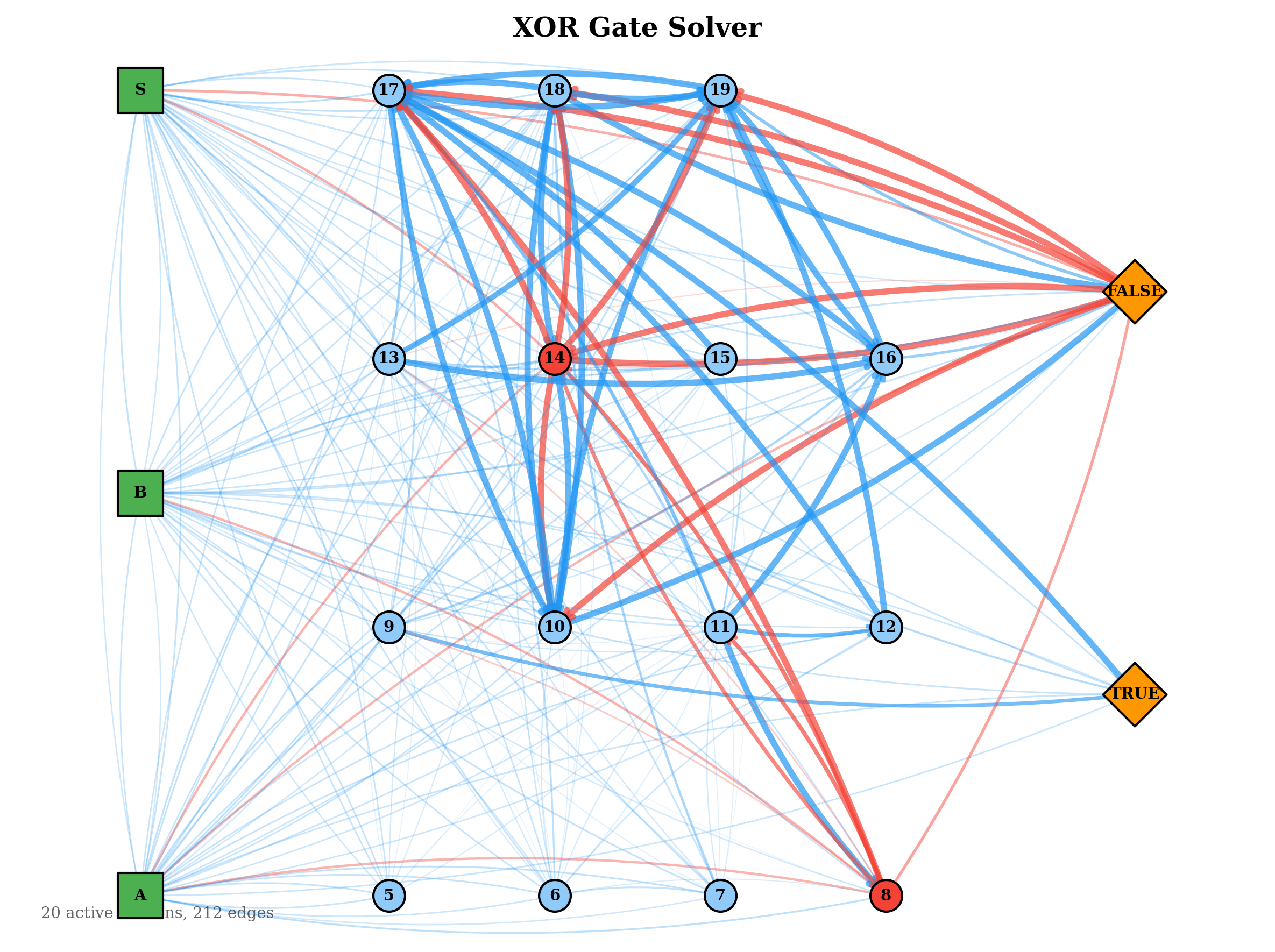
These results also suggest that an in-life constructive topology mechanism — one that adds neurons dynamically during training — is not strictly necessary. However, it would be beneficial as currently one has to guess at the number of required neurons within the hyperparameters. Some of the above graphs, especially NOT, did not take full advantage . The current barrier is the lack of spatial locality: neurons have no position, so proximity-based wiring heuristics cannot be applied directly. A workable substitute might be temporal locality or spatial zones — for instance, designating border neurons that can form connections with neurons in adjacent zones, serving as a computationally inexpensive proxy for spatial proximity, creating a S-CNG or a Spatial CNG. This warrants further investigation.
During prototyping I tried a few different experiments to hone the final evolutionary model. One of these was inputting the gates sequentially which actually converged much faster. As this was not my planned experiment I changed to the current continuous input, however, this seems to suggest that the model, at least on a very microscale, is able to react to nonconcurrent inputs. This would roughly match biological systems as we can get overwhelmed and also scan, being able to cut inputs. Further research is needed. In addition, I tested two sequence memory where the graph needed to repeat the sequence fully in order to prevent brute forcing. The graph hit around 50% accuracy, however, neuron thresholds rapidly collapsed to an average between 0.017 and 0.02. Out of curiosity I fed higher number sequences up to 20 into the best graph with it achieving 50% accuracy on random sequences of length 10. This points to inhibitory neurons as essential for short-term memory formation and therefore of fundamental importance to the architecture's long-term potential. In addition, it also provides a road of further study to determine if this prototyping result was indicative of true short-term memory.
Limitations
A primary limitation of this architecture is that inputs and outputs are natively binary. Because spiking neurons are either on or off, any non-binary information must be encoded as binary or one-hot input, which restricts the range of tasks the graph can directly address.
A second limitation is that evolutionary progress is vulnerable to bad luck. A strong graph can be eliminated by stochastic variation before it fully develops, necessitating Catastrophic Extinction recovery runs. Lamarckian Evolution is also inherently slower at topology search than pure NEAT, since it must balance in-life learning continuity with evolutionary exploration. The current mitigation — initializing each run with a large scatter-shot population — wastes compute on graphs that will never converge but have not yet been culled.
Additionally, because neuron count does not evolve, it must be set by hand at initialization. Estimating the right number is feasible only for simple tasks; for more complex functions it becomes pure guesswork, leading to either under-provisioned graphs that cannot learn the task or over-provisioned graphs that waste capacity. This problem is not unique to the CNG — the transformer architecture similarly requires manual sizing — but it remains a meaningful constraint.
Another limitation discovered during the experiment was that even with this simple function, some of the graphs suffered catastrophic forgetting which does not bode well for the ability of the graph to handle more complex tasks permanently. More research will have to be done on the best ways to reduce or vary plasticity in a way that enables learning while still preventing catastrophic forgetting.
Finally, this experiment leaves two important capabilities undemonstrated. First, while the model permits continual sequential learning, no such capabilities were demonstrated. Second, while the CNG is theoretically capable of scaling to larger graphs, this experiment used only twenty neurons per graph. How the architecture — and in particular the scatter-shot evolutionary approach — scales to thousands or millions of neurons remains unknown.
Conclusion
Transformers are fundamentally stateless, non-continuous systems. While they can use context to simulate temporal sequences and continuity, they are inherently non-persistent. This limits their ability to form new memories or experience time as an ongoing process.
In this work I explored an alternative architecture designed to address these limitations, combining a continuously operating graph with multiple interlocking learning mechanisms to produce a cohesive whole. The CNG maintains internal state continuously, supports in-life learning without interrupting operation, and is theoretically capable of developing short-term memory. The system successfully learned all five Boolean operations and displayed early signs of memory-like behavior during prototyping.
While the architecture remains limited in scope and requires further research, initial results support the viability of a stateful, continuously operating system. Rather than recomputing from scratch on every input, the CNG carries its internal state forward in time.