I have at times dabbled in playing 2048. While, I was never very good at the game, it struck me as a game that could be played purely algorthimically more so than any other games. So when I decided that I would like to teach myself neural networks and reinforcement learning, it seemed to me to be the ideal game to utilize as an avenue for creating a reinforcement learning algorthimn.
2048 is a game where one is presented with a four by four grid of cells. Within each cell a number can appear either two or four. One can swipe, moving all of the cells in the direction swiped. When two of the same number collide, they combine, adding themselves resulting in only one number occupying one cell. Combining these larger and larger numbers while ensuring that one does not run out of moves is the main game loop.
In order to create this game, I utilized the library Pygame to handle the main game loop and inputs while pandas would be used for its dataframes. The heart of the game is the gameboard which is a four by four dataframe containing the number of the tile within each cell. Upon initializing the game, Pygame, utilizes this dataframe to determine which graphic should be displayed within the four by four grid. The color of the tile is likewise modified based upon the picture pulling from a dictionary which defined up to a number so large I presumed no human that would play my game would ever get to. Pressing one of the keys will determine the range and step of the iteration based upon the key pressed. With this information it will then move the values in the desired direction until they have either hit a wall or a different value. There is then a seperate check to see if any values which are adjascent in that direction are identicle, where upon they are merged.
The AI receives as its input from sixteen inputs into the first layer utilizing ReLU activation. This is a flattened version of the gameboard where each of the input values represents a tile on the gameboard. This is passed through a middle linear layer again utilizing ReLU activation before it is outputed to four values using the raw Q-values to determine the direction in which the AI will move the board.
The AI is granted a reward for the score at the end of its turn. This is counteracted by a punishment for having tiles filled regardless of my value. Finally, there is a large punishment for performing a move which does not actually move any tiles. It was my hope that this combination of rewards and punishments would mean that the AI would both prioritize reaching as high a score as possible while avoiding allowing the board to be filled. In addition, the final punishment would highly discourage the AI from racking up points by spamming a move that doesn't move any of the tiles and accumulating reward.
That was the final iteration, the first iteration did not have a punishment for having cells full. In addition, the neural network was half as complex. I trained this model for approximately 2000 episodes with the following results.
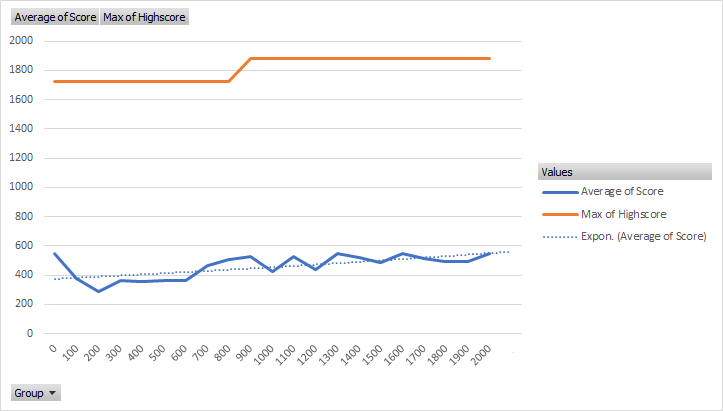
As one can see, there was a slight increase of the model's capability as time went on. However, interestingly enough, the most successful average was during the first 100 generations. As such, I presumed that upon further training, the model would increase. However, as this training took eighteen and a half hours, I wished to simplify the model. In addition, I added the slight punishment for having the board filled, presuming that this punishment would assist the AI. I halved the complexity of the model and ran another test from scratch which ran for twenty hours reaching 2350 generations with the following results.
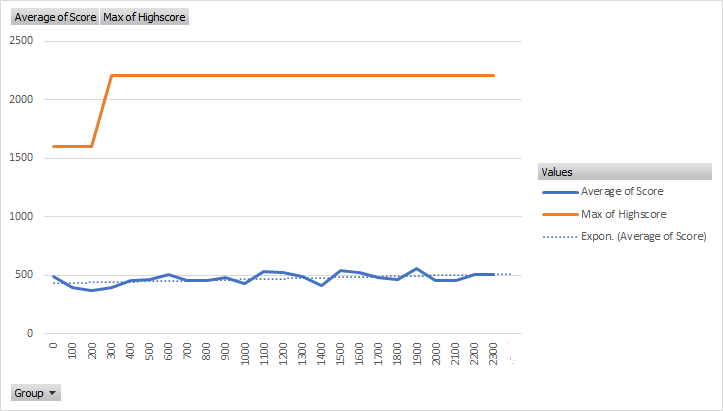
As we can see, while the climb of the trend was less, it started out at a higher average score. In addition, it took twenty hours to train, which meant that I did not see the appreciable gain in speed that I desired. These two results meant that while I saw the additional punishment as promising, I did not see enough benefits from the simplification to run a much longer test. As such, I increased the complexity of the model radically. I added an additional inner layer as well as increasing the size of the first layer to 128 with the second layer being a size of 64. This model however crashed several times as such I was unable to advance the training beyond the 550th episode. The results are shown belowe.
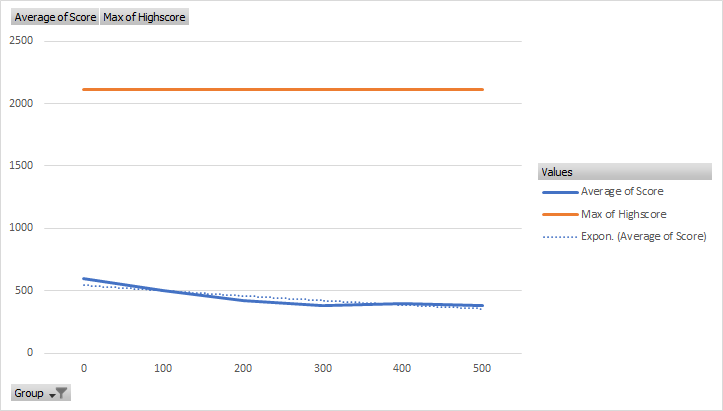
The trendline of this third version of the model displayed that it actually decayed over time in the average score. In addition, the high score set during the first 100 episodes remained the high score throughout. This shows that while the model was initially atleast just as effective if not slightly more so than the other two tested models, it decayed, most likely due to over fitting. As this project was the first of my neural networks, I was unaware of other measures to reduce the risk of over fitting, this combined with the crashes, lead to me reducing the complexity in layers, while increasing the actual neurons to 256 within the single layer.
I decided to run this model, along with an increase in the punishments for having full cells upon the board, for a prodigious amount of time, as I had learned how to use neural networks and reinforcement learning and desired to move on from the project. This was combined with my school break ending and thus my spare time to work on the model with it. As such, I ran this model for 281 hours, which is just under twelve days, in the background of my computer. I arrived at the following results.
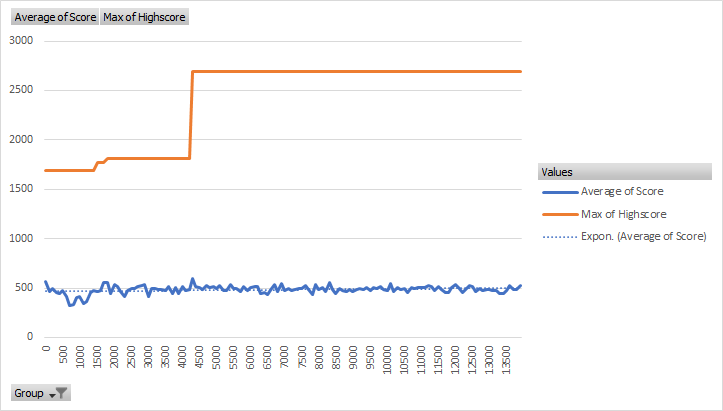
These results were to say the least dissapointing. While, there was no decay in the model, the slope of the trendline was extremely small. Indeed, I did not even detect a trend until I added a line, with the average continually hovering around five hundred except for a few hundred generations at the start where the model took a dive in performance. As such, I can confidently say that the model failed to improve even over the course of thousands of episodes. This is most likely because of over fitting, as the simpler models actually performed better, but with me out of time, I called the project here.
The project, however, was not a failure for me, as it gave me valuable experience in creating neural networks. In addition, it helped me to understand that bigger isn't always better. This would serve me well in my school work where I had to create other neural networks, this time for language processing. Perhaps, I will return to this project, armed with new knowledge and experience, and finally achieve my goal of having an AI that can destroy any human at the game.